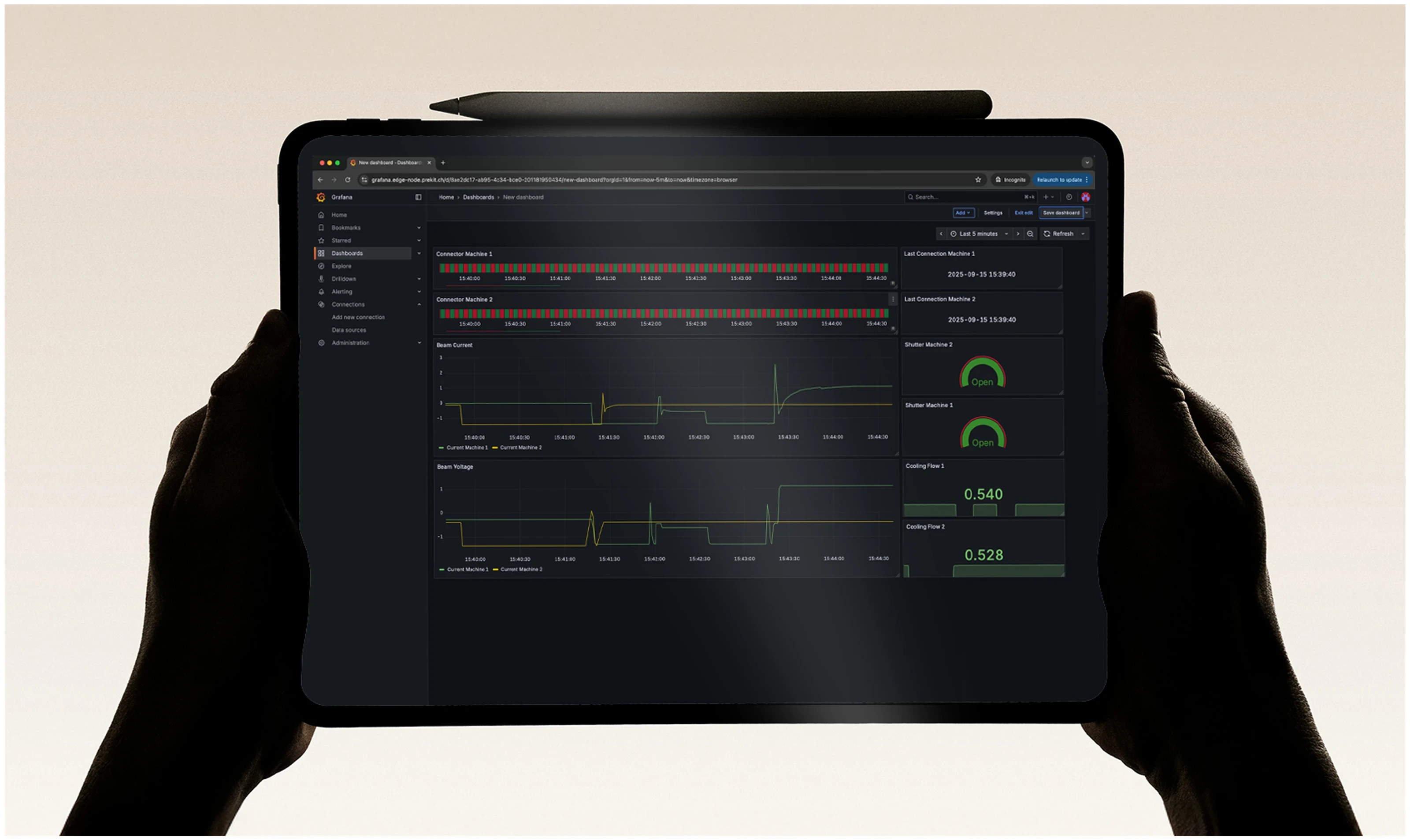

In einer Industrie-4.0-Architektur fungiert ein Historian wie das Langzeitgedächtnis der Produktion. Während der Unified Namespace (UNS) immer den aktuellen Zustand Ihrer Anlagen, Sensoren und Prozesse zeigt, sammelt und speichert der Historian fortlaufend alle relevanten Daten über längere Zeiträume hinweg.
Was bringen solche Daten?
In meiner Erfahrung werden historische Daten umso wertvoller, je zugänglicher sie für die richtigen Leute sind. Der Historian erlaubt es Prozessexperten und Produktionsleitern, vergangene Maschinen- und Prozessdaten geordnet abzurufen. Anstatt mühselig alte Tabellen oder verstreute Aufzeichnungen zu durchforsten und auszuwerten, stehen dir in Visualisierungstools wie Grafana dann verlässliche und vollständige Informationen jederzeit zur Verfügung.
Ganz konkret:
Das Engineering bei einem Kunden hat in den historischen Daten aus dem Betrieb seiner Anlagen erkannt, dass die Motoren ihrer Maschinen von Kunden nur selten nahe ihrer Nennleistung genutzt wurden. In der nächsten Produktgeneration konnten die Motoren kleiner dimensioniert werden – ohne Einbußen bei der Performance. Das spart nicht nur Kosten für das Unternehmen und seine Kunden, sondern schont auch die Umwelt.
Im Vorfeld einer wichtigen Messe nutzte das Marketingteam eines Kunden historische Daten, um entscheidende Verkaufsargumente für die eigene Automatisierungslösung zu schaffen. Denn die Daten belegten: die Lösung spart Energie und führt zu einer besseren Qualität.
Ein Projektpartner setzt mit einem Kunden ein ambitioniertes Machine-Learning-Projekt um, mit dem Ziel, mehrere kritische Fehlerarten in der Stahlfertigung vorherzusagen. Eine InfluxDB auf der Edge sammelt und speichert alle Datenpunkte, auf die es ankommt.
Je nach Einsatzzweck kann ein Historian auf unterschiedliche Art realisiert werden
Edge Historian: Dieser befindet sich direkt an der Anlage oder in der Fabrikhalle. Er zeichnet lokale Prozesswerte auf, liefert schnelle Einblicke in aktuelle Geschehnisse und unterstützt kurzfristige Analysen – etwa um sofort auf Veränderungen reagieren zu können.
Enterprise Historian: Hier werden Daten mehrerer Produktionslinien oder gar -Standorte zentral zusammengeführt und harmonisiert. Der Historian liefert ein umfassendes Gesamtbild, ermöglicht Vergleiche zwischen verschiedenen Anlagen oder erleichtert das Erkennen von Zusammenhängen über die gesamte Prozesskette hinweg.
Data Lakes als „Historian“: Ein Data Lake ist eine große, oft Cloud-basierte Datenablage, in der alle Zeitreihen-Ereignisse (Maschinendaten, Logbuch-Einträge, Qualitätsinformationen) ohne starre Strukturen gespeichert werden. Zwar benötigt man zusätzliche Tools, um Daten für Analysen oder Visualisierungen aufzubereiten, doch bietet ein Data Lake enorme Flexibilität und Skalierbarkeit – besonders bei komplexen Auswertungen oder Machine-Learning-Modellen.
Historian Software kaufen oder Open Source Datenbanken nutzen?
Der Gedanke, der eigenen Fertigung ein Langzeitgedächtnis zu verleihen, ist kein neuer. Auch bevor „reif für den KI-Einsatz“ als Zielgröße in IT-Strategien auftauchte, erkannten viele Produktionsleiter und Prozessexperten das Potenzial in der Ursachenforschung und Prozessoptimierung, wenn Prozessdaten langfristig gespeichert werden.
Mit dem Anwendungsfall Historian gehen einige Spezialanforderungen an die Datenspeicherung einher:
In Fertigungsprozessen entstehen in kürzester Zeit enorme Datenmengen. Bei den ca. 100 Maschinen in der “Smart Factory” von Rittal sind das z. B. 16 Terabyte Rohdaten pro Tag. Damit Datenbanken performant bleiben, müssen Fragen geklärt werden wie: Welche Daten werden als Rohdaten abgespeichert und welche aggregiert? Reichen mir die verlustfreien Komprimierungsalgorithmen der Datenbank – oder akzeptiere ich einen gewissen Informationsverlust zugunsten stärkerer Kompression?
Üblicherweise strebt man an, jeden Datenpunkt („Tag“) mit seiner Bedeutung zu verknüpfen. Das heißt: Ausgehend vom Temperaturwert eines Sensors (z. B. PT344X2) sollte nachvollziehbar sein, welches Systemelement gemessen wurde, in welcher Einheit (°C oder °F) und in welchem Bereich der Sensor arbeitet – auch wenn sich die Fertigung im Wandel befindet.
Spezialisierte Historian-Softwarelösungen (z. B. Canary Labs, AVEVA, OSIsoft PI) wurden entwickelt, um diese Anforderungen von Haus aus zu erfüllen. Doch man braucht keine dedizierte Historian-Software, um einen Historian zu realisieren. Immer mehr Unternehmen setzen auf Open-Source-Technologien.
Eine tiefere Erklärung, warum das sinnvoll sein kann, liefert Jeremy Theocharis vom United Manufacturing Hub in diesem Video.
In der Praxis könnte das ganz konkret so aussehen
Ein Datenlogger sammelt nahezu in Echtzeit alle relevanten Prozessdaten deiner Maschine und streamt sie über MQTT, wo eine InfluxDB (zeitreihenoptimierte Datenbank) unmittelbar an der Maschine auf Updates hört und diese speichert (Edge Historian).
Wichtige Datenpunkte werden aggregiert und gemeinsam mit den Daten weiterer Produktionsprozesse, Auftragsdaten und Qualitätsdaten in einer SQL-Datenbank im Unternehmensnetzwerk gespeichert (Enterprise Historian).
Damit die Datenbanken nicht zu groß werden, landen alte Zeitreihen komprimiert als Parquet-Dateien im Data Lake – ebenso Bilddaten und Dokumente. Von dort können sie jederzeit für Visualisierung und Analyse geladen werden.